
import torch
model = torch.hub.load('huawei-noah/Efficient-AI-Backbones', 'snnmlp_t', pretrained=True)
# or
# model = torch.hub.load('huawei-noah/Efficient-AI-Backbones', 'snnmlp_s', pretrained=True)
# or
# model = torch.hub.load('huawei-noah/Efficient-AI-Backbones', 'snnmlp_b', pretrained=True)
model.eval()
All pre-trained models expect input images normalized in the same way,
i.e. mini-batches of 3-channel RGB images of shape (3 x H x W), where H and W are expected to be at least 224.
The images have to be loaded in to a range of [0, 1] and then normalized using mean = [0.485, 0.456, 0.406]
and std = [0.229, 0.224, 0.225].
Here’s a sample execution.
# Download an example image from the pytorch website
import urllib
url, filename = ("https://github.com/pytorch/hub/raw/master/dog.jpg", "dog.jpg")
try: urllib.URLopener().retrieve(url, filename)
except: urllib.request.urlretrieve(url, filename)
# sample execution (requires torchvision)
from PIL import Image
from torchvision import transforms
input_image = Image.open(filename)
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model
# move the input and model to GPU for speed if available
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
model.to('cuda')
with torch.no_grad():
output = model(input_batch)
# Tensor of shape 1000, with confidence scores over Imagenet's 1000 classes
print(output[0])
# The output has unnormalized scores. To get probabilities, you can run a softmax on it.
print(torch.nn.functional.softmax(output[0], dim=0))
Model Description
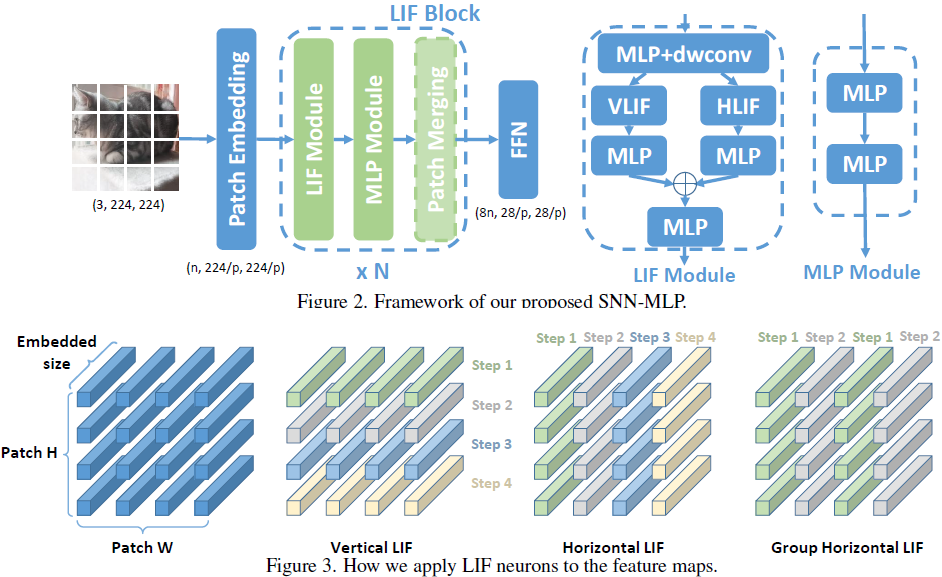
SNNMLP incorporates the mechanism of LIF neurons into the MLP models, to achieve better accuracy without extra FLOPs. We propose a full-precision LIF operation to communicate between patches, including horizontal LIF and vertical LIF in different directions. We also propose to use group LIF to extract better local features. With LIF modules, our SNNMLP model achieves 81.9%, 83.3% and 83.6% top-1 accuracy on ImageNet dataset with only 4.4G, 8.5G and 15.2G FLOPs, respectively.
The corresponding accuracy on ImageNet dataset with pretrained model is listed below.
| Model structure | #Parameters | FLOPs | Top-1 acc |
|---|---|---|---|
| SNNMLP Tiny | 28M | 4.4G | 81.88 |
| SNNMLP Small | 50M | 8.5G | 83.30 |
| SNNMLP Base | 88M | 15.2G | 85.59 |
References
You can read the full paper here.
@inproceedings{li2022brain,
title={Brain-inspired multilayer perceptron with spiking neurons},
author={Li, Wenshuo and Chen, Hanting and Guo, Jianyuan and Zhang, Ziyang and Wang, Yunhe},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={783--793},
year={2022}
}
